Dogwheels
Status: Draft
This piece is an experiment — I'm working on getting comfortable publishing less polished work, so this draft was written quickly & published right away.
This is a note about a data visualization I came up with while exploring ways to visualize dog names. It's a kind of generalized ternary plot.
In 2012 I joined an up-and-coming startup that had just spun out of the MIT Media Lab to commercialize research into vector space models of meaning. At MIT the founding team had created and open-sourced ConceptNet, a giant database of common-sense facts about the world represented in the form of a semantic network. The idea behind the company was to combine data from ConceptNet with text from other documents to create a "blended" semantic space that represented both, e.g. to help make sense of collections of product reviews, using ConceptNet as background knowledge to fill in the gaps in the data.
This is all just background to explain why, in 2018, when I found myself in New York City submitting a FOIA request to the Department of Health and Mental Hygiene for data on all licensed dogs, I knew what I had to do. Amusingly, the commissioner of this department at the time was named Commissioner Basset.
The data duly arrived and I found myself in possession of several years' worth of dog names for all the (licensed) dogs in New York. I soon published a visualization of name–breed associations in The Long Tail of Dog Names (note the "googly eyes?" checkbox in the bottom left corner).
This post is about another picture I made around the same time, which I dubbed a "dogwheel", and which combines the power of ConceptNet with the power of dogs to put dog names into semantic space.
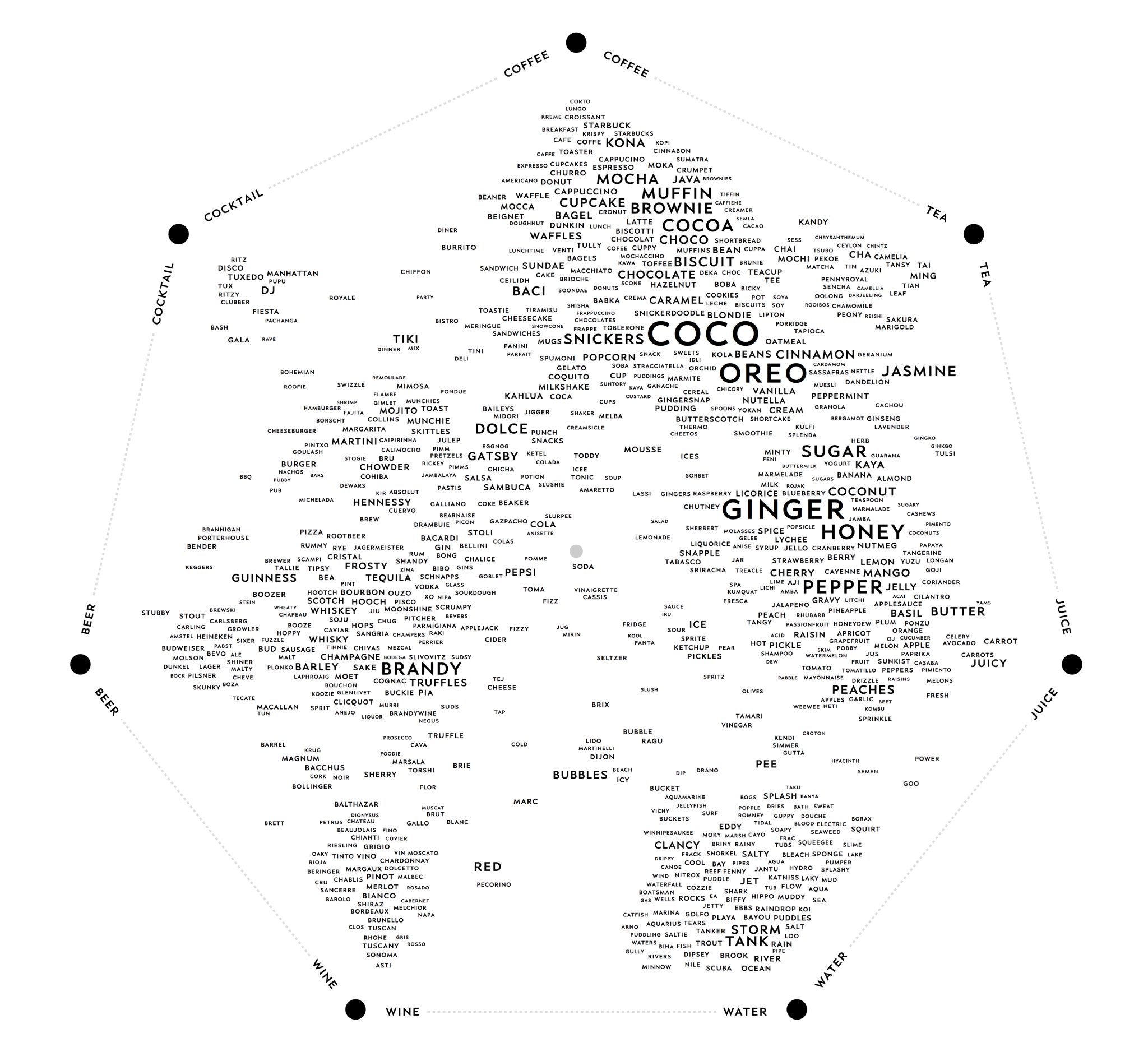
Here is a dogwheel of drinks:

These aren't just food & drink names – each one is also a bona-fide dog name in New York City. The idea here is that you pick a set of concepts – in this case, types of drinks – which are placed at the corners of a regular polygon. These form a "concept space" inside which dog names are placed based on the strength of their connections to those concepts.
Here's a close-up:

Click here to see the full-size dogwheel.
{kind=link}
In the pictures above, each label is a dog name whose position depends on that name's relationship to the corner concepts. For example, note the proximity of the name "Starbuck" to the coffee corner, and how close "Carrot" is to juice. The size of each name depends on the number of dogs with that name – larger text means more dogs.
How does it work?
Here's a high-level overview of the basic idea:
Pick a set of N points (vectors) in the high-dimensional space to be the "corner" concepts.
We want to project them down to 2D by fixing each of those points to an associated position in 2D (in our case, the corners of a regular polygon).
As an intermediate representation, it is useful to map each of these N high-dimensional points to an N-D set of "corner weights" — this transformation should be one that maps the first corner point to [1 0 0 0 0], the second one to [0 1 0 0 0], and so on. If we can map an arbitrary high-dimensional point into this basis, then we can position that point inside the regular polygon using a second matrix multiplication to map the point to its coordinates in the regular polygon.
If the corner points were orthogonal then this transformation would be the identity matrix, and we could map non-corner concepts into the lower-dimensional space (2D) directly by taking the dot product with each corner concept. Since the corner concepts are in general not orthogonal, however, we instead compute this mapping by inversing its inverse, which is easy to directly construct.
To do this, we define the "reverse" mapping from the identity matrix of corner weights to the N high-dimensional points (vectors), which is the matrix where each column is a corner vector.
We then take the Penrose-Moore Pseudoinverse (pinv) of this matrix. Intuitively, you can imagine the process of going from 4D high-dimensional space to a 3D "corner basis" as picking three 4D points as the corner concepts and using pinv to find the mapping that transforms them exactly to our "corner weight" positions of [1, 0, 0], [0, 1, 0], and [0, 0, 1]. This transformation, given by the pseudoinverse, gives us a way to carry any 4D point into 3D, representing it in the same basis, ie. as a linear combination of the corner concepts.
From there, since each corner concept also has an associated 2D coordinate, we can translate the N-D point down to 2D using another matrix multiplication.
(Note: It would be great to have a worked example of this, or at least some pictures to illustrate the process, or an explanation of the intuitive idea behind the pseudoinverse. The explanation above is taken from contemporaneous notes, and I can't say I fully follow it myself right now, since it's been a few years...)
Concept selection
The number of dog names is very large and not all of them have to do with the corner concepts. We don't want to put unrelated dogs into the dog wheel. How should we pick which names should be selected to appear in the visualization?
The approach I took for this prototype was to include any name with a sufficiently high dot product with any of the individual corner concepts, playing with the cutoffs until they gave reasonable results.
Concept sizing
I sized each dog name by the number of dogs that had that name. The font size was determined by the square root of the dog name frequency. There's a bit of fuzz here since longer names take up more space at the same font size, so it's an imperfect proxy for saliency.
Concept ordering
The order of the concepts around the wheel is important because concepts have relationships to each other and e.g. if two closely-related concepts were to be put on opposite sides of the wheel this would have a very negative effect on the positions of concepts inside the wheel.
The ideal ordering would do something like minimize the differences between adjacent concepts. In my prototype, I brute-forced this computation since we have only seven or so concepts. If I remember, the specific error metric I used was the sum of the dot products between adjacent concepts.
Concept positioning
In ordinary ternary plots you have two dimensions and two degrees of freedom — the plot visualizes three variables but they're constrained to sum to 1, so any two determine the third. This means that every position inside the plot represents a unique combination of the corner coordinates.
Our generalization of ternary plots means that a 2D position no longer has a unique location in the higher-dimensional space.
Because concepts in a semantic space are often weakly related, many concepts wind up in the ambiguous region near the middle where the semantics aren't quite easy to read off, and the corners stay mostly unoccupied.
To combat this effect I applied a fisheye-like distortion to move concepts away from the center and towards the corners to semantically emphasize their strongest components. Concept positions were also modified by the layout algorithm since we don't want the dog names to overlap. I used a modified version of the standard JavaScript word cloud library for layout since I needed to constrain the positions to lie within the regular polygon.
Future Extensions
I'd like to try this visualization on other datasets, eg. taking online discussion comments and projecting them into a wheel of emotions.
There's a cool paper about using a TSP solver to compute an optimal circuit around the concepts. It would be interesting to try something like this to compute the optimal concept ordering with respect to an appropriate error metric.
The current visualization maps the "corner concepts" to corners of a regular polygon. While this has aesthetic merit it can result in a distorted picture of the conceptual relationships since some corner concepts are more related to each other than others are, but all corners are spaced equally apart. It would be interesting to relax the constraint and allow irregular polygons, eg. positioning the corner concepts around a circle in a way that more accurately preserves their relative distances.
I also wonder whether there's any way, given a dataset, to automatically find good sets of corner concepts. This would mean finding concepts that make intuitive sense as a group, and whose relationships spread the data apart in a meaningful way. The chart above was my favorite out of a large set of variations. With this kind of visualization it is not the case that any set of corner concepts yields an enlightening plot.
Thanks to Ben Cartwright-Cox for valuable assistance with the FOIA process as well as being an excellent source of ideas for what to do with the dogs once we got them, and to Andrew Lin, who suggested using pinv as the projection mechanism as well as the brute-force search + error metric approach to concept ordering (I was previously plotting the data using something more akin to standard ternary plots where for each name I took its dot product with all the corner concepts, normalized this vector by its sum to turn it into a composition, and then projected down to the polygon, which accomplished something similar but in a mathematically less elegant way).
Notes to self
-
See conversation with Andrew over gmail on October 8, 2019 which explains the idea behind pinv.
-
The contemporaneous notes I based this article on are from here. There are more screenshots in various pages in Notion; search Dogwheel. Eg. this one.
-
Subset the web fonts, perhaps as part of the production build process. They are large.
-
I did this with:
-
pnpm install -g glyphhanger
-
python3 -m pip install fonttools
-
python3 -m pip install brotli
-
python3 -m pip install zopfli
-
glyphhanger --subset=./PragmataPro_Mono_R_liga_0829.woff2 --format=woff2 --LATIN
-
glyphhanger --subset=./PragmataPro_Mono_Z_liga_0829.woff2 --format=woff2 --LATIN
-
glyphhanger --subset=./PragmataPro_Mono_B_liga_0829.woff2 --format=woff2 --LATIN
-
glyphhanger --subset=./PragmataPro_Mono_I_liga_0829.woff2 --format=woff2 --LATIN
-
-
-
To do
-
Have a better process for picking a reasonable font subset depending on the article. Maybe Latin will always work, but I'm not sure.
-
I wonder if there is a simple way to pick up the article title from the bike file itself rather than having to specify it separately in the JavaScript.