For many years I used the Julia programming language for transforming, cleaning, analyzing, and visualizing data, doing statistics, and performing simulations.
I published a handful of open-source packages for things like signed distance fields, nearest-neighbor search, and Turing patterns (among others), made visual explanations of Julia concepts like broadcasting and arrays, and used Julia to make the generative art on my business cards.
I stopped using Julia a while ago, but it still sometimes comes up. When people ask, I tell them that I can no longer recommend it. I thought I’d write up my reasons why.
My conclusion after using Julia for many years is that there are too many correctness and composability bugs throughout the ecosystem to justify using it in just about any context where correctness matters.
In my experience, Julia and its packages have the highest rate of serious correctness bugs of any programming system I’ve used, and I started programming with Visual Basic 6 in the mid-2000s.
It might be useful to give some concrete examples.
Here are some correctness issues I filed:
Here are comparable issues filed by others:
copyto! methods don’t check for aliasingI would hit bugs of this severity often enough to make me question the correctness of any moderately complex computation in Julia.
This was particularly true when trying a novel combination of packages or functions — composing together functionality from multiple sources was a significant source of bugs.
Sometimes the problems would be with packages that don’t compose together, and other times an unexpected combination of Julia’s features within a single package would unexpectedly fail.
For example, I found that the Euclidean distance from the Distances package does not work with Unitful vectors. Others discovered that Julia’s function to run external commands doesn’t work with substrings. Still others found that Julia’s support for missing values breaks matrix multiplication in some cases. And that the standard library’s @distributed macro didn’t work with OffsetArrays.
OffsetArrays in particular proved to be a strong source of correctness bugs. The package provides an array type that leverages Julia’s flexible custom indices feature to create arrays whose indices don’t have to start at zero or one.
Using them would often result in out-of-bounds memory accesses, just like those one might encounter in C or C++. This would lead to segfaults if you were lucky, or, if you weren’t, to results that were quietly wrong. I once found a bug in core Julia that could lead to out-of-bounds memory accesses even when both the user and library authors wrote correct code.
I filed a number of indexing-related issues with the JuliaStats organization, which stewards statistics packages like Distributions, which 945 packages depend on, and StatsBase, which 1,660 packages depend on. Here are some of them:
The majority of sampling methods are unsafe and incorrect in the presence of offset axes
Fitting a DiscreteUniform distribution can silently return an incorrect answer
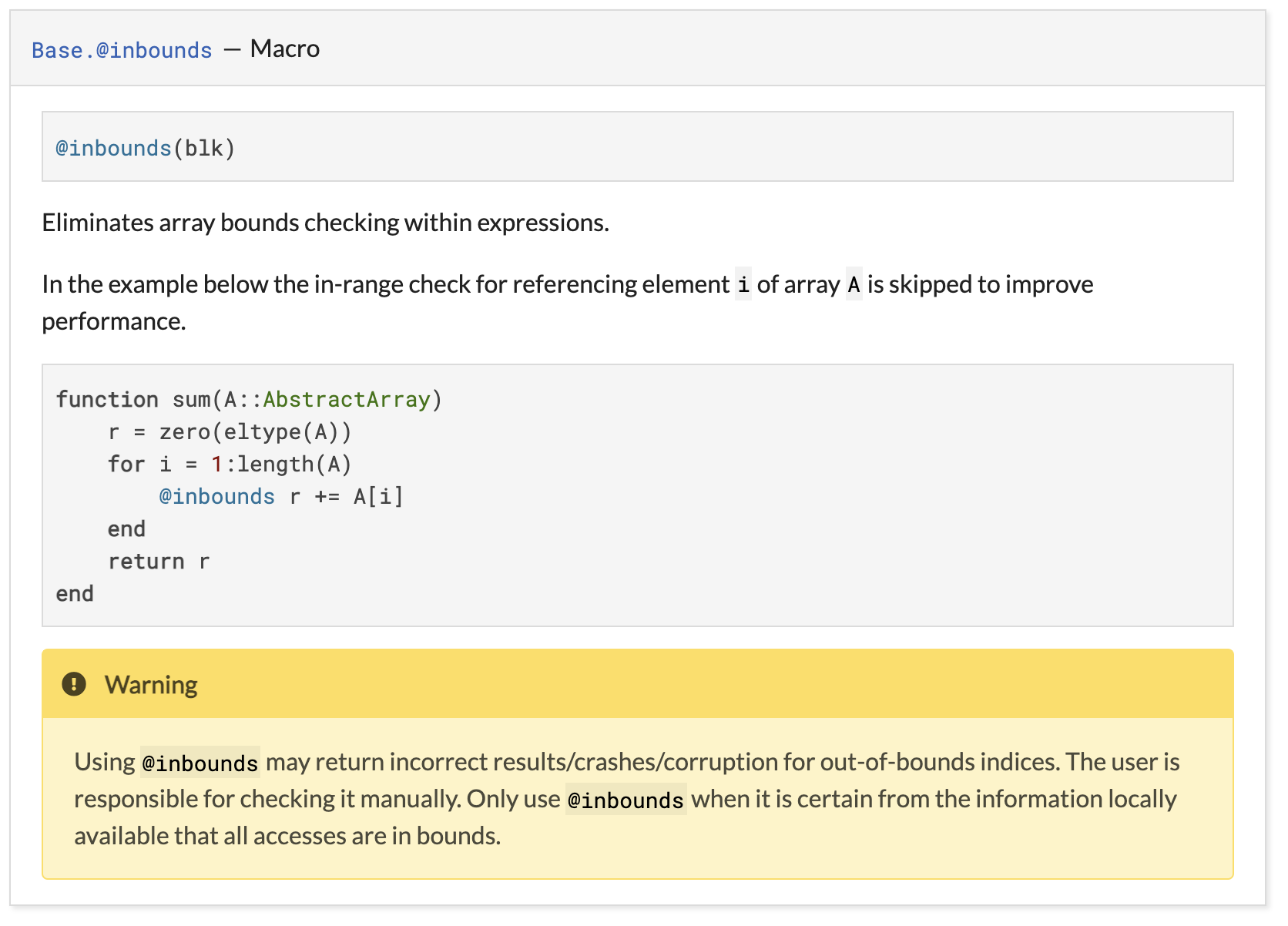
Incorrect uses of @inbounds cause miscalculation of statistics
Showing a Weights vector wrapping an offset array accesses out-of-bounds memory
The root cause behind these issues was not the indexing alone but its use together with another Julia feature, @inbounds, which permits Julia to remove bounds checks from array accesses.
For example:
function sum(A::AbstractArray)
r = zero(eltype(A))
for i in 1:length(A)
@inbounds r += A[i] # ← 🌶
end
return r
end
The code above iterates i from 1 to the length of the array. If you pass it an array with an unusual index range, it will access out-of-bounds memory: the array access was annotated with @inbounds, which removed the bounds check.
The example above shows how to use @inbounds incorrectly. However, for years it was also the official example of how to use @inbounds correctly. The example was situated directly above a warning explaining why it was incorrect:
That issue is now fixed, but it is worrying that @inbounds can be so easily misused, causing silent data corruption and incorrect mathematical results.
In my experience, issues like these were not confined to the mathematical parts of the Julia ecosystem.
I encountered library bugs while trying to accomplish mundane tasks like encoding JSON, issuing HTTP requests, using Arrow files together with DataFrames, and editing Julia code with Pluto, Julia’s reactive notebook environment.
When I became curious if my experience was representative, a number of Julia users privately shared similar stories. Recently, public accounts of comparable experiences have begun to surface.
For example, in this post Patrick Kidger describes his attempt to use Julia for machine learning research:
It’s pretty common to see posts on the Julia Discourse saying “XYZ library doesn’t work”, followed by a reply from one of the library maintainers stating something like “This is an upstream bug in the new version a.b.c of the ABC library, which XYZ depends upon. We’ll get a fix pushed ASAP.”
Here’s Patrick’s experience tracking down a correctness bug (emphasis mine):
I remember all too un-fondly a time in which one of my Julia models was failing to train. I spent multiple months on-and-off trying to get it working, trying every trick I could think of.
Eventually – eventually! – I found the error: Julia/Flux/Zygote was returning incorrect gradients. After having spent so much energy wrestling with points 1 and 2 above, this was the point where I simply gave up. Two hours of development work later, I had the model successfully training… in PyTorch.
In a discussion about the post others responded that they, too, had similar experiences.
Like @patrick-kidger, I have been bit by incorrect gradient bugs in Zygote/ReverseDiff.jl. This cost me weeks of my life and has thoroughly shaken my confidence in the entire Julia AD landscape. [...] In all my years of working with PyTorch/TF/JAX I have not once encountered an incorrect gradient bug.
Since I started working with Julia, I’ve had two bugs with Zygote which have slowed my work by several months. On a positive note, this has forced me to plunge into the code and learn a lot about the libraries I’m using. But I’m finding myself in a situation where this is becoming too much, and I need to spend a lot of time debugging code instead of doing climate research.
Given Julia’s extreme generality it is not obvious to me that the correctness problems can be solved. Julia has no formal notion of interfaces, generic functions tend to leave their semantics unspecified in edge cases, and the nature of many common implicit interfaces has not been made precise (for example, there is no agreement in the Julia community on what a number is).
The Julia community is full of capable and talented people who are generous with their time, work, and expertise. But systemic problems like this can rarely be solved from the bottom up, and my sense is that the project leadership does not agree that there is a serious correctness problem. They accept the existence of individual isolated issues, but not the pattern that those issues imply.
At a time when Julia’s machine learning ecosystem was even less mature, for example, a co-founder of the language spoke enthusiastically about using Julia in production for self-driving cars:
And while it’s possible that attitudes have shifted since I was an active member, the following quote from another co-founder, also made around the same time, serves as a good illustration of the perception gap (emphasis mine):
I think the top-level take away here is not that Julia is a great language (although it is) and that they should use it for all the things (although that’s not the worst idea), but that its design has hit on something that has made a major step forwards in terms of our ability to achieve code reuse. It is actually the case in Julia that you can take generic algorithms that were written by one person and custom types that were written by other people and just use them together efficiently and effectively. This majorly raises the table stakes for code reuse in programming languages. Language designers should not copy all the features of Julia, but they should at the very least understand why this works so well, and be able to accomplish this level of code reuse in future designs.
Whenever a post critiquing Julia makes the rounds, people from the community are often quick to respond that, while there have historically been some legitimate issues, things have improved substantially and most of the issues are now fixed.
For example:
These responses often look reasonable in their narrow contexts, but the net effect is that people’s legitimate experiences feel diminished or downplayed, and the deeper issues go unacknowledged and unaddressed.
My experience with the language and community over the past ten years strongly suggests that, at least in terms of basic correctness, Julia is not currently reliable or on the path to becoming reliable. For the majority of use cases the Julia team wants to service, the risks are simply not worth the rewards.
Ten years ago, Julia was introduced to the world with an inspiring and ambitious set of goals. I still believe that they can, one day, be achieved—but not without revisiting and revising the patterns that brought the project to the state it is in today.
Thanks to Mitha Nandagopalan, Ben Cartwright-Cox, Imran Qureshi, Dan Luu, Elad Bogomolny, Zora Killpack, Ben Kuhn, and Yuriy Rusko for discussions and comments on earlier drafts of this post.