Visualizing Sentences with Finite State Automata
The National Electronic Injury Surveillance System in the US collects data on product-related injuries. It has a dataset of emergency room visits, with granular information on over 8.5 million visits across 100 hospitals going back over 20 years.
An interesting feature of the data is that each ER visit comes with a narrative story. For example:
A 50YOF DROPPED A CRYSTAL BALL ON FOOT, SPRAINED FOOT
PATIENT ROLLED OFF BED, HIT EAR ON DRESSER OR ON WOODEN KNOB SHAPED LIKE AN ELEPHANT HEAD AT HOME; EAR LAC.
2 NIGHTS AGO A FRIEND MICROWAVED A MARSHMALLOW AND PUT IT ON PT’S NECKPT HAS BURN TO NECK WITH BLISTERING
One way to get a qualitative sense of what’s in this dataset is to do some thematic keyword searches. For example, for bicycles:
PT FELL OFF BICYCLE AND HIT HEAD
PT RIDING BICYCLE AND FELL AND LAC ARM
13YOBF FELL OFF BICYCLE;RADIAL HEAD FX
Avocados:
PT CUTTING AN AVOCADO AND LAC HAND ON KNIFE
LAC FINGER ON KNIFE CUTTING AVOCADO
CUT WITH KNIFE TO FINGER WHILE CUTTING AVOCADOSDX: LAC FINGER PT
Cowboy boots:
PT DANCING IN COWBOY BOOTS STRAINED RIGHT ANKLE
PT. HAS FOOT DISFIGUREMENT FROM CHRONIC COWBOY BOOT WEARING. DX:FOOT DISFIGUREMENT
PATIENT WAS ACCIDENTALLY KICKED IN RIBS PLAYING WITH FRIENDS WHOWORE COWBOY BOOTS. DX. RIGHT RIB CAGE STERNAL SOFT TISSUE.
Banana peels:
WALKING DOWN HANDICAP RAMP CARRYING BOXES AND STEPPED ON A BANANA PEELAND FELL STRAINING KNEE
32 YO FEMALE SLIPPED ON BANANA PEEL AND FELL TO FLOORKNEE STRAIN
PT SLIPPED ON BANANA PEEL AND FELL ON FLOOR IN STORE
I wanted to visually summarize the variation within sets of similar stories like these, and after tinkering a bit realized that this problem was very similar to a collaboration I was a part of a while ago that focused on visualizing variations across a set of lede sentences in newspaper articles. One of the goals there was to reveal authorial/media bias, which led us to stay close to the surface texts since phrase ordering and word choice are part of how bias is expressed. In the ER visit stories, though, the texts are written in medicalese and the event semantics matter more than surface syntax, so I think it would be fine to dramatically restructure the text if doing so reveals interesting higher-level patterns. It’s also possible that visualizing something like the temporal sequence of events and their consequences directly will wind up being a good idea here.
The story so far
After getting the dataset into shape I spent some time learning about minimal finite state acceptors, which I thought could be a mechanism for merging similar sentence fragments together. FSAs compactly represent a set of strings by reusing suffixes wherever possible:
Input:
Yuri accidentally went to the store
Ruby deliberately went to the store
Output:
Yuri accidentally ⤵
went to the store
Ruby deliberately ⤴
This post by Andrew Gallant has a great overview of FSA construction and usage. In the section on FSA construction Andrew visualizes the algorithm for constructing a minimum finite-state acceptor for a given set of strings. I implemented the algorithm described in the post, which comes from a paper called Incremental Construction of Minimal Acyclic Finite State Automata , and tried it out on some of the stories from the emergency room data.
My plan was to see whether FSAs could be used to capture the variation in a curated set of sentences based on a search term, such AVOCADO or BOOTS.
An issue that came up is that, since each node in an FSA represents a fixed set of strings, finite state automata will only compress strings if they share a suffix. For example, the following two sentences cannot be compressed using an FSA because they differ in their last word:
Yuri accidentally went to the bar
Ruby deliberately went to the store
One way around this is to focus the compression on a local neighborhood around the word of interest (eg. WENT above) and to build two automata: one for the prefix leading up to the word, and another for the reversed suffix of the word. The reversal of the suffix makes it so that the “end” of the FSA is closest to the word of interest, which often leads to a more compact automaton.
For example, here’s a pair of FSAs for BOOTS, visualizing local neighborhoods across 10 sentences: 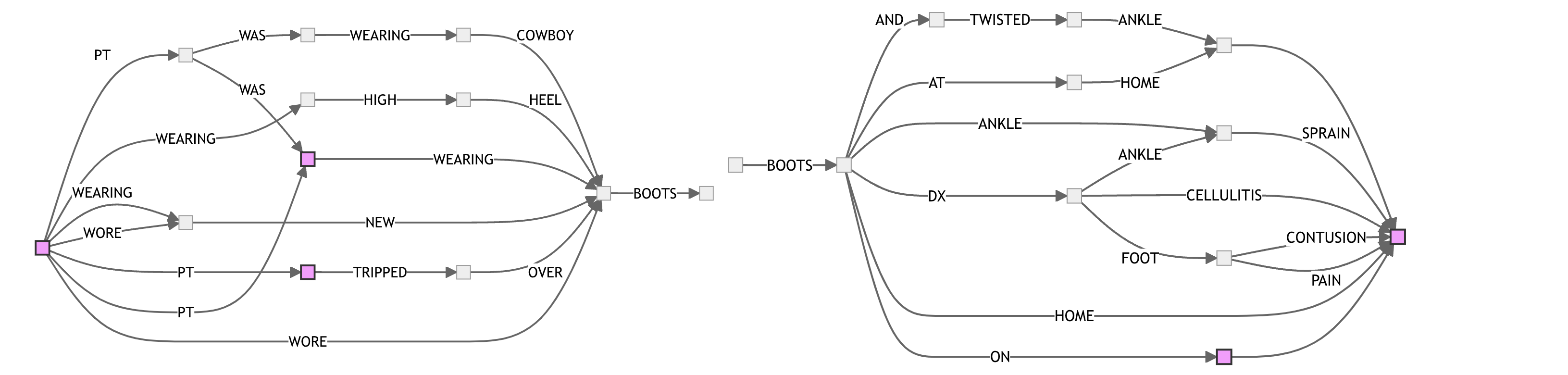
Here’s BOOTS with 20 sentences: 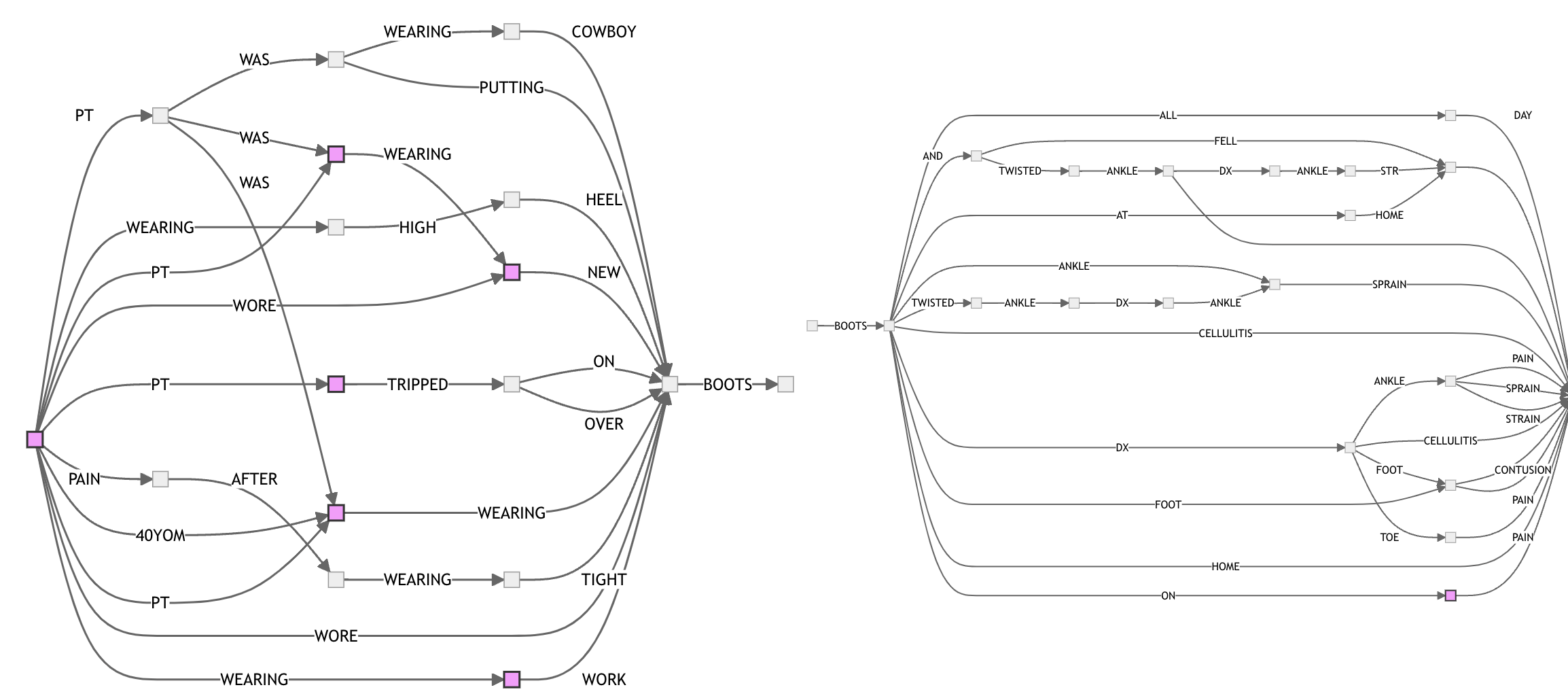
And here’s BICYCLE with 25 sentences: 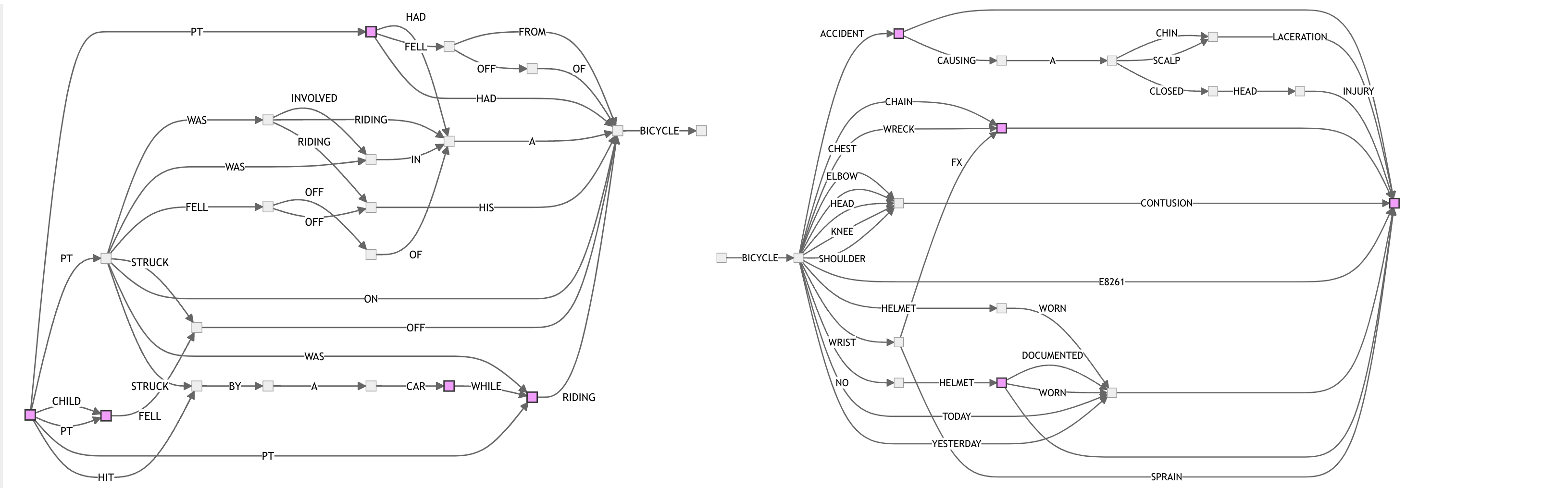
It feels like there’s a glimmer of promise here, but I need to do some more thinking about how to proceed.
One idea is to use LLMs to conform the sentences to a more standard structure, then build automata for each “semantic fragment” of the sentence, and visualize the result using something like a parallel coordinates plot with ordinal Y axes.
Another thing I want to try is to identify collocations (multi-word phrases like “christmas tree”) and use those as the elements over which the FSA is built, rather than always simple-mindedly splitting on word boundaries.
There’s also a lot of work to do on visual presentation. The current diagrams are just the raw output from Mermaid and are hard to read. Perhaps there’s a layout algorithm that is a better match for this family of graphs. My suspicion is that, in the end, the visualization should look significantly less graph-like, with the FSA graph serving as more of an inner structure to guide layout decisions. Related:
First there is old work by Book and Chandra, with the following abstract.
Summary. It is shown that for every finite-state automaton there exists an equivalent nondeterministic automaton with a planar state graph. However there exist finite-state automata with no equivalent deterministic automaton with a planar state graph.
I wonder if it would be reasonable to “planarize” nonplanar FSA graphs by duplicating nodes and edges. I’d like to make it easier to read these from left to right without so much eye movement, and being able to lay sentences out without intersection seems like it would help.
A few things this project reminds me of:
- The data is similar to that underlying some visualizations I worked on for large collections of distributed traces. For that effort we aggregated individual traces into a prefix tree, with edges representing service dependencies. (FSAs are compressed representations of prefix trees).
- One of the powerful ideas in that project was that we built service-centric views that merged together all of the prefix tree nodes for the target service in postprocessing, which is similar to what I did above in building the prefix trees for the prefix/suffix of a local window around the target word.
- Both forms of merging result in ambiguous graphs. I think this is fine so long as there is a way to disambiguate interactively – it could let us scale to much larger sentence sets.
- This post on dominator trees.
- The Gyllenhaal Experiment, which visualizes people’s attempts to spell a famous person’s name: